
Click on above Image
Header Ads

Data Science Process

Data Science Process
The data science process typically consists of six steps
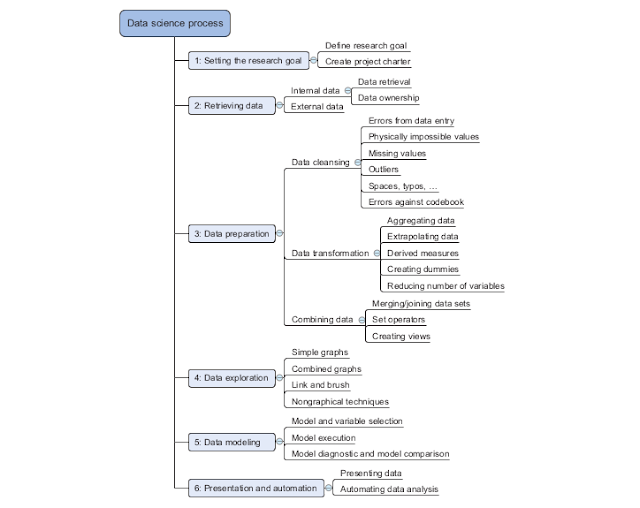
1. Setting the Research Goal
The first step of this process is setting a research goal. The main purpose here is
making sure all the stakeholders understand the what, how, and why of the project. In every serious project this will result in a project charter.
Defining research goal
An essential outcome is the research goal that states the purpose of your assignment in a clear and focused manner.
Understanding the business goals and context is critical for project success.
Create project charter
A project charter requires teamwork, and your input covers at least the following:
- A clear research goal
- The project mission and context
- How you’re going to perform your analysis
- What resources you expect to use
- Proof that it’s an achievable project, or proof of concepts
- Deliverables and a measure of success
- A timeline
2. Retrieving Data
The second phase is data retrieval. You want to have data available for analysis, so this step includes finding suitable data and getting access to the data from the data owner. The result is data in its raw form, which probably needs polishing and transformation before it becomes usable.
Data can be stored in many forms, ranging from simple text files to tables in a database. The objective now is acquiring all the data you need. This may be difficult, and even if you succeed, data is often like a diamond in the rough: it needs polishing to be of any use to you.
Start with data stored within the company.
The data stored in the data might be already cleaned and maintained inrepositories such as databases, data marts, data warehouses and data lakes.
Don't be afraid to shop around
- If the data is not available inside the organization, look outside your organization walls.
Do data quality checks now to prevent problems later
- Always double check while storing your data if it is an internal data. If it is an external data prepare the data such a way that it could be easily extracted.
3. Data Preparation
The data preparation involves Cleansing, Integrating and transforming data
Cleansing Data
Data cleansing is a sub process of the data science process that focuses on removing errors in your data so your data becomes a true and consistent representation of the processes it originates from.
- Interpretation error - Example a age of a person can be greater than 120
- Inconsistencies- Example is mentioning the Gender as Female in one column and F in another column but both tend to mention the same
Data Entry Errors - Data collection and data entry are error-prone processes. They often require human intervention, and because humans are only human, they make typos or lose their concentration for a second and introduce an error into the chain.
Redundant White space - White spaces tend to be hard to detect but cause errors like other redundant characters would. White spaces at the beginning of a word or at a end of a word is much hard to identify and rectify.
Impossible values and sanity checks - Here the data are checked for physically and theoretically impossible values.
Outliers - Here the data are checked for physically and theoretically impossible values. An outlier is an observation that seems to be distant from other observations or, more specifically, one observation that follows a different logic or generative process than the other observations.
Dealing with the Missing values - Missing values aren’t necessarily wrong, but you still need to handle them separately; certain modelling techniques can’t handle missing values.
Techniques used to handle missing data are given below

Correct as early as possible
- Decision-makers may make costly mistakes on information based on incorrect data from applications that fail to correct for the faulty data.
- If errors are not corrected early on in the process, the cleansing will have to be done for every project that uses that data.
- Data errors may point to defective equipment, such as broken transmission lines and defective sensors.
- Data errors can point to bugs in software or in the integration of software that may be critical to the company.
Combining data from different sources
- Data from different model can be combined and stored together for easy cross reference.
- There are different ways of combining the data.
- Joining Tables
- Appending Tables
- Using views to simulate data joins and appends
Transforming Data
Certain models require their data to be in a certain shape.
Data Transformation - Converting a data from linear data into sequential or continuous form of data

Reducing the number of variables - Having too many variables in your model makes the model difficult to handle, and certain techniques don’t perform well when you overload them with too many input variables.
Turning variables into Dummies
4. Data Exploration
Information becomes much easier to grasp when shown in a picture, therefore you mainly use graphical techniques to gain an understanding of your data and the interactions between variables.
Examples
Pareto diagram is a combination of the values and a cumulative distribution.

Histogram : In it, a variable is cut into discrete categories and the number of occurrences in each category are summed up and shown in the graph.

Boxplot : It doesn’t show how many observations are present but does offer an impression of the distribution within categories. It can show the maximum, minimum, median, and other characterising measures at the same time.
5. Data Modelling or Model Building
With clean data in place and a good understanding of the content, you’re ready to build models with the goal of making better predictions, classifying objects, or gaining an understanding of the system that you’re modelling.
Building a model is an iterative process. Most models consist of the following main steps:
- Selection of a modelling technique and variables to enter in the model
- Execution of the model
- Diagnosis and model comparison
Model and variable selection
The model has to be built upon the following aspects
- Must the model be moved to a production environment and, if so, would it be easy to implement?
- How difficult is the maintenance on the model: how long will it remain relevant if left untouched?
- Does the model need to be easy to explain?
Model Execution - Once you’ve chosen a model you’ll need to implement it in code.

6. Presentation and Automation
After you’ve successfully analysed the data and built a well-performing model, you’re ready to present your findings to the world. This is an exciting part all your hours of hard work have paid off and you can explain what you found to the stakeholders.


0 Comments